Multi-View Stereo by Temporal Nonparametric Fusion
https://aaltoml.github.io/GP-MVS/
Problem: Accurate, real-time dense depth estimation from monocular sequence
Idea: Similar views should have similar representations in latent-space
Solution: Soft-constrain bottleneck layer of depth estimation network using Gaussian Procceses (GPs) with appropriate pose-kernel
First, we go into the problem of estimating depth for a single view (using multiview constraints in this case)
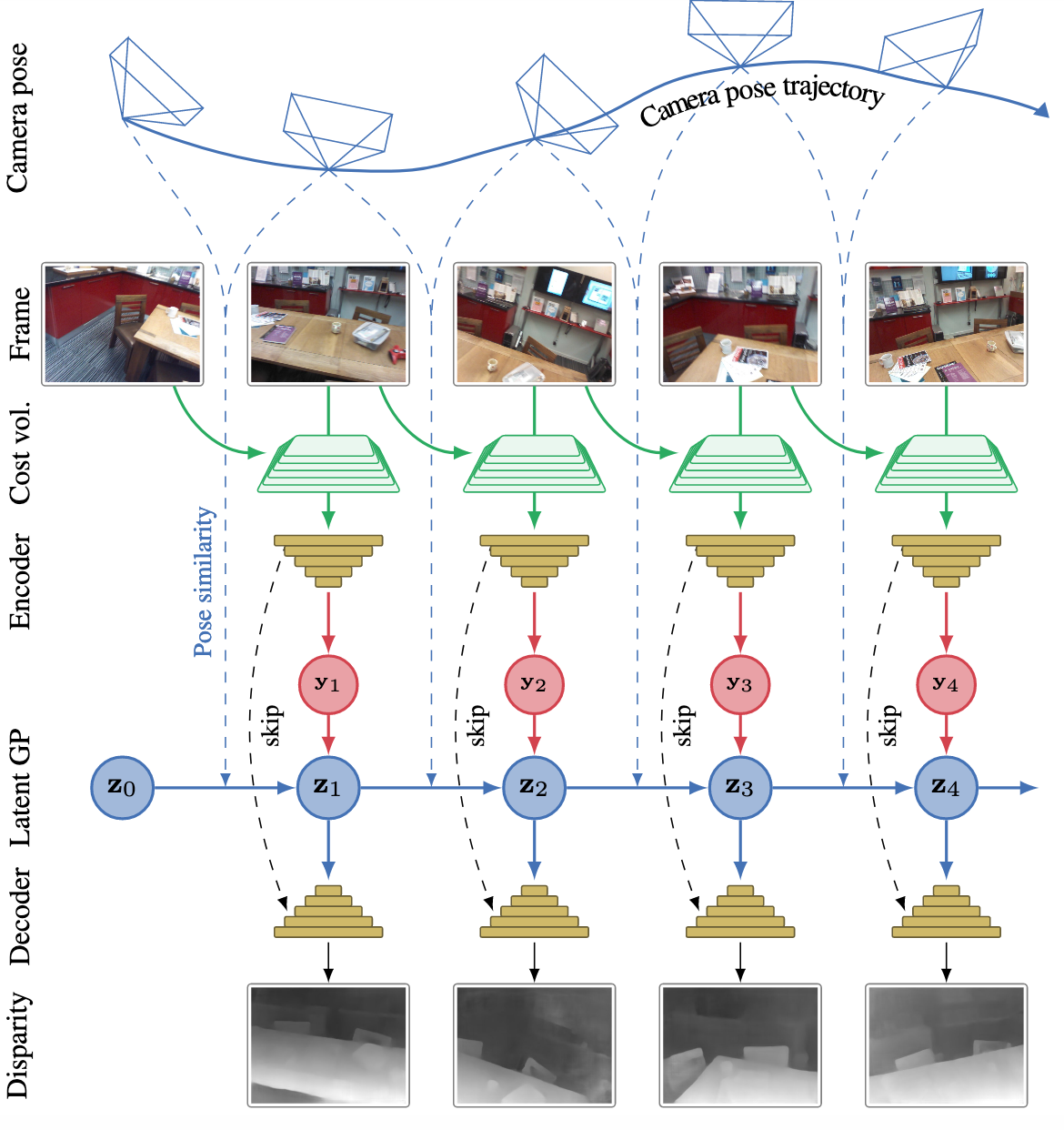
Network Architecture for Single Frame Depth Estimation
Exact same architecture as in MVDepthNet: Real-time Multiview Depth Estimation Neural Network
Problem: Leverage multiview geometry in real-time dense depth network (assuming known poses of images from odometry source)
Idea: Cost volumes can directly encode geometric constraints so that networks don't have to
Solution: Feed cost volume along with input image into network
Methods prior to this work:
- Single-view methods do not generalize well due to lack of constraints
- Difficult to parameterize epipolar geometry into network
- Cannot easily augment dataset due to multiview constraints
Cost Volume Construction
- Construct cost-volume with respect to a reference frame and auxiliary frames
- Discretize inverse depth (here using 64 values)
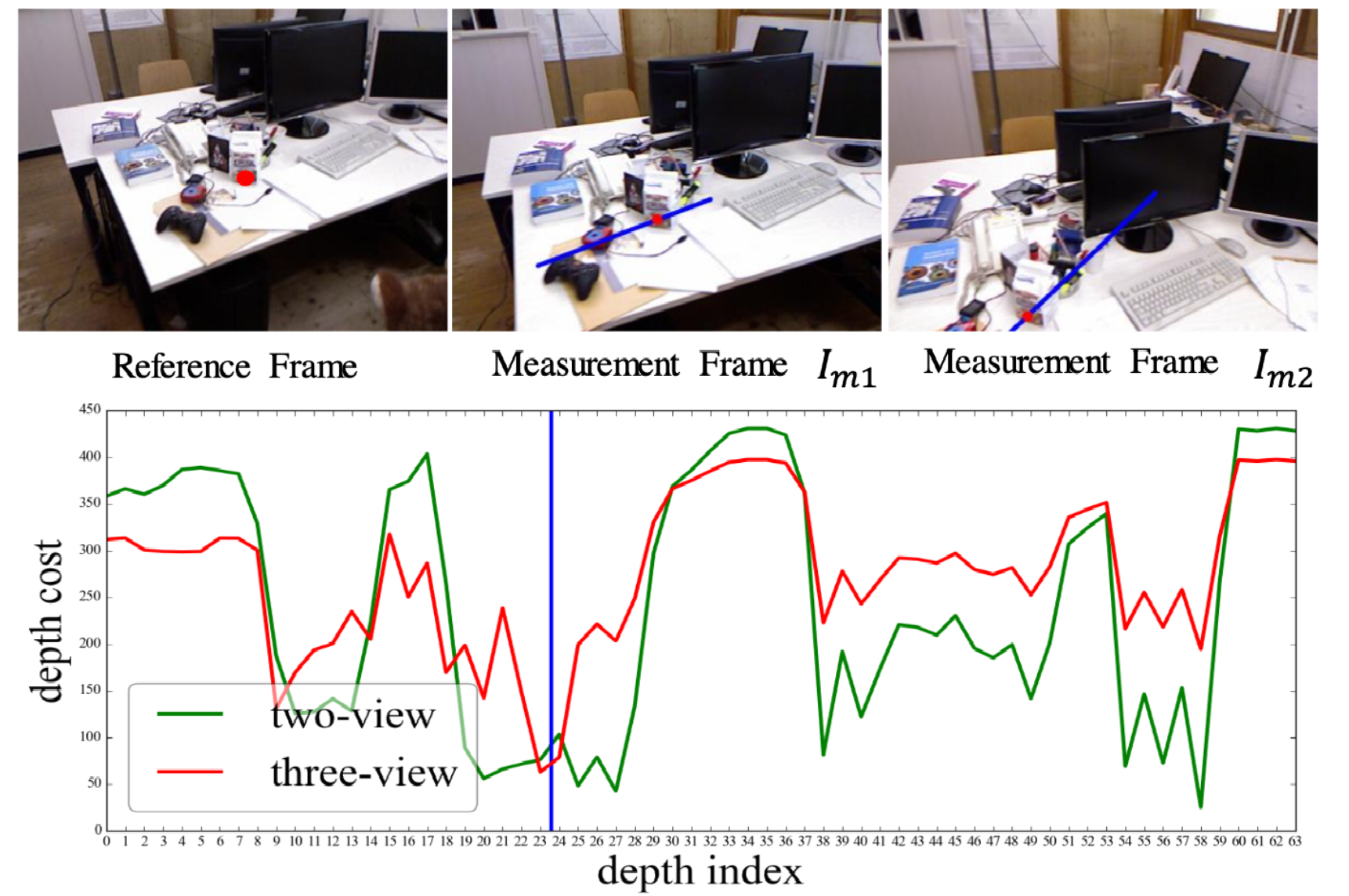
- Note: No window size used for cost aggregation (only single pixel used) so that details are preserved
Network Architecture
Feed RGB reference frame (depth 3) and cost volume (depth 64) into encoder-decoder network with skip connections
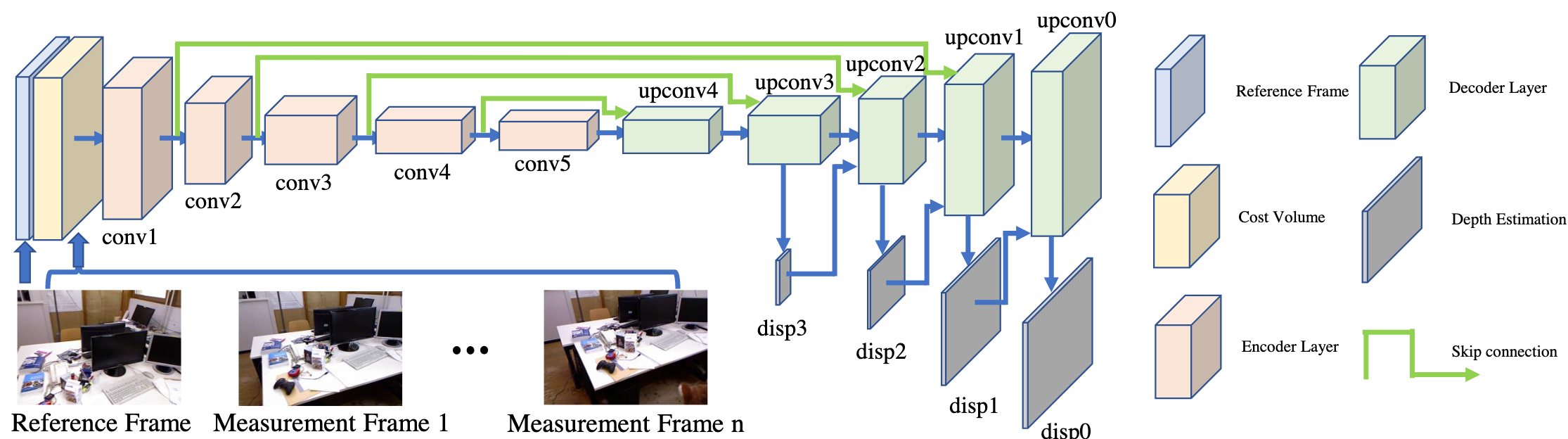
Data augmentation is now straightforward because all inputs and ground-truth are with respect to the same frame
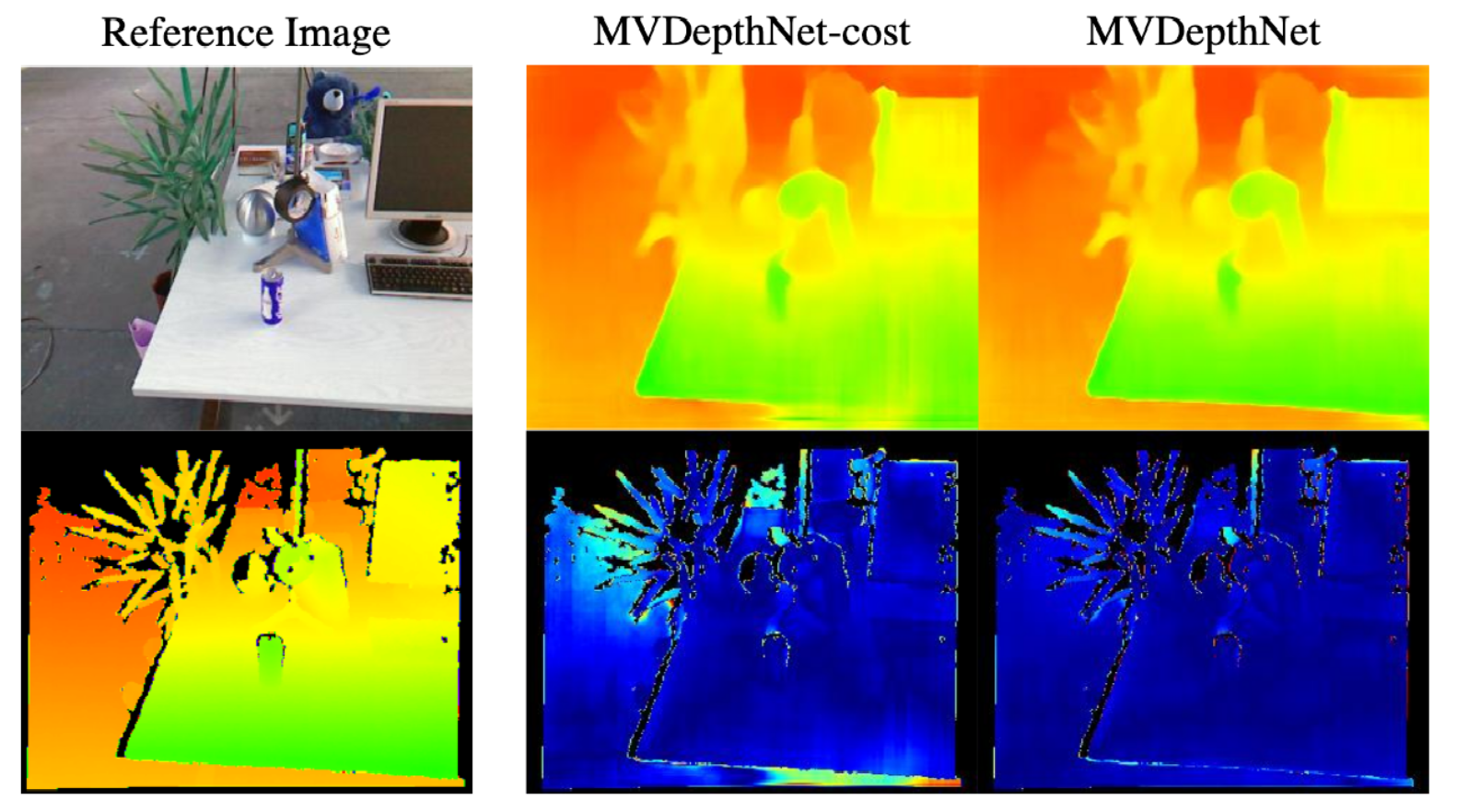
Notable Ablation Studies
Example of how adding RGB image to inputs provides finer details as compared to cost-volume alone:
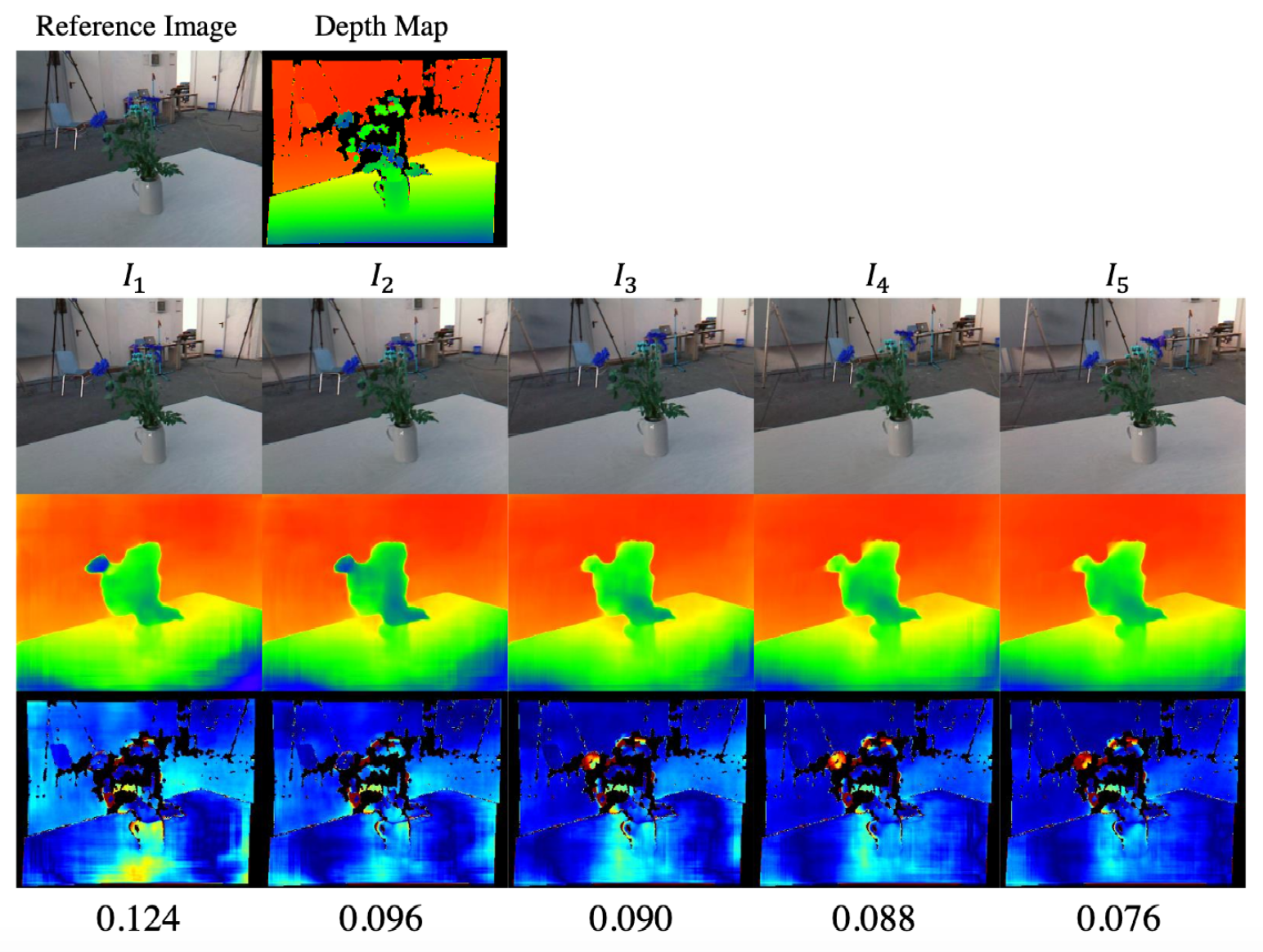
Impact of number of auxiliary frames on accuracy of depth estimation:
Problems
- While MVDepthNet uses a window of frames, it cannot leverage information beyond this window
- If places revisited, will attempt independent estimation of depth and lack consistency
- To address this issue, latent representations can enforce temporal consistency between different frames
Pose-Kernel Gaussian Process Prior
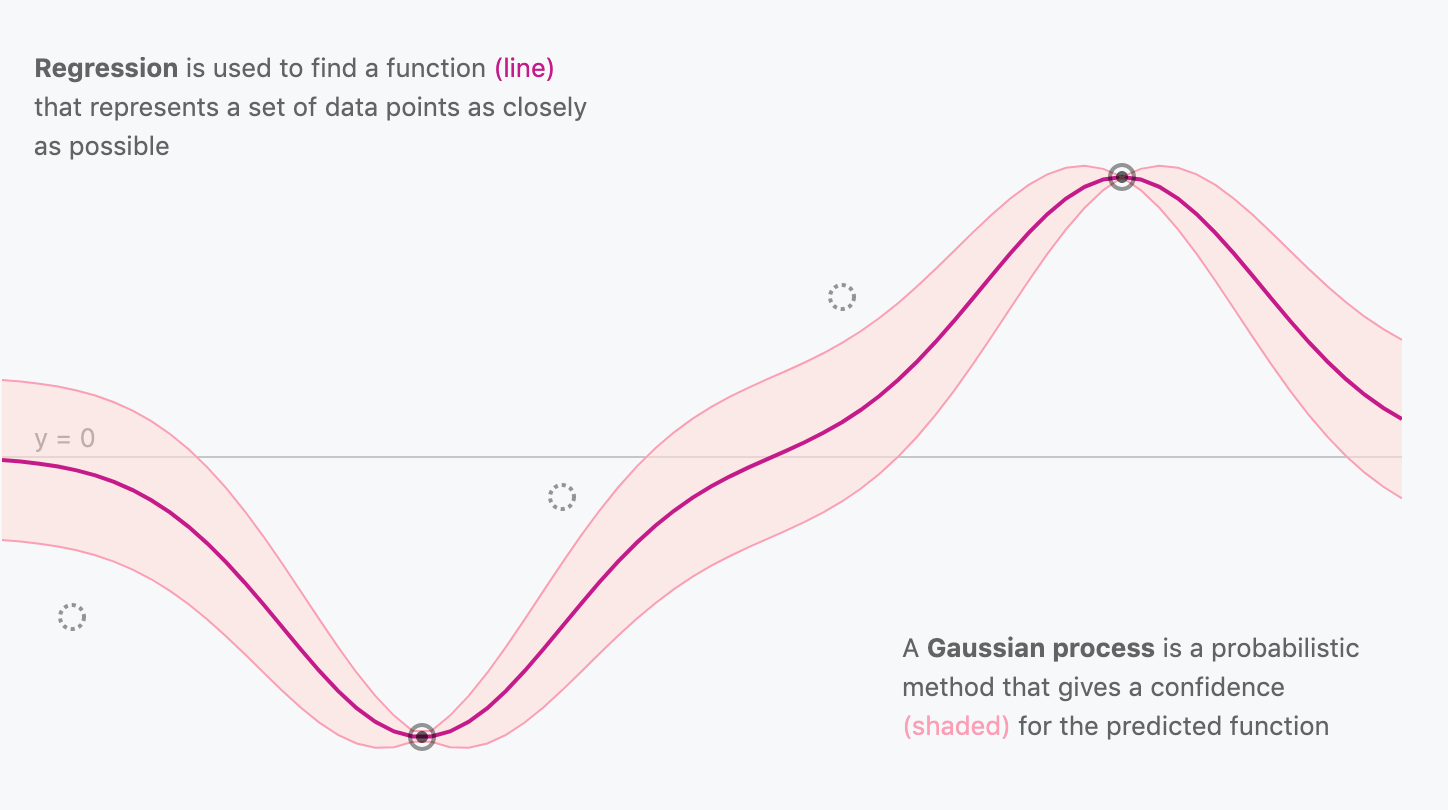
Gaussian Process Reminder
- Nonparametric method often used for regression
- Observed function values can be used to infer posterior distribution over functions
- Condition on training data to retrieve predictions for test data
Figure generated using https://distill.pub/2019/visual-exploration-gaussian-processes/
Pose Kernel
- For kernel to assess similarity between poses, we need some a distance metric between rigid-body poses:
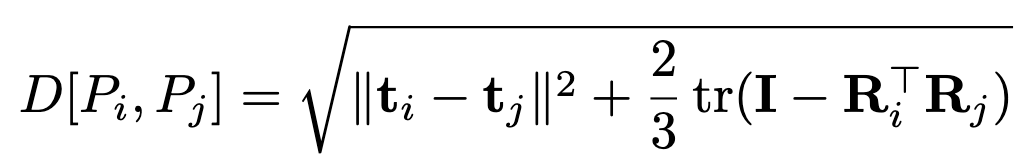
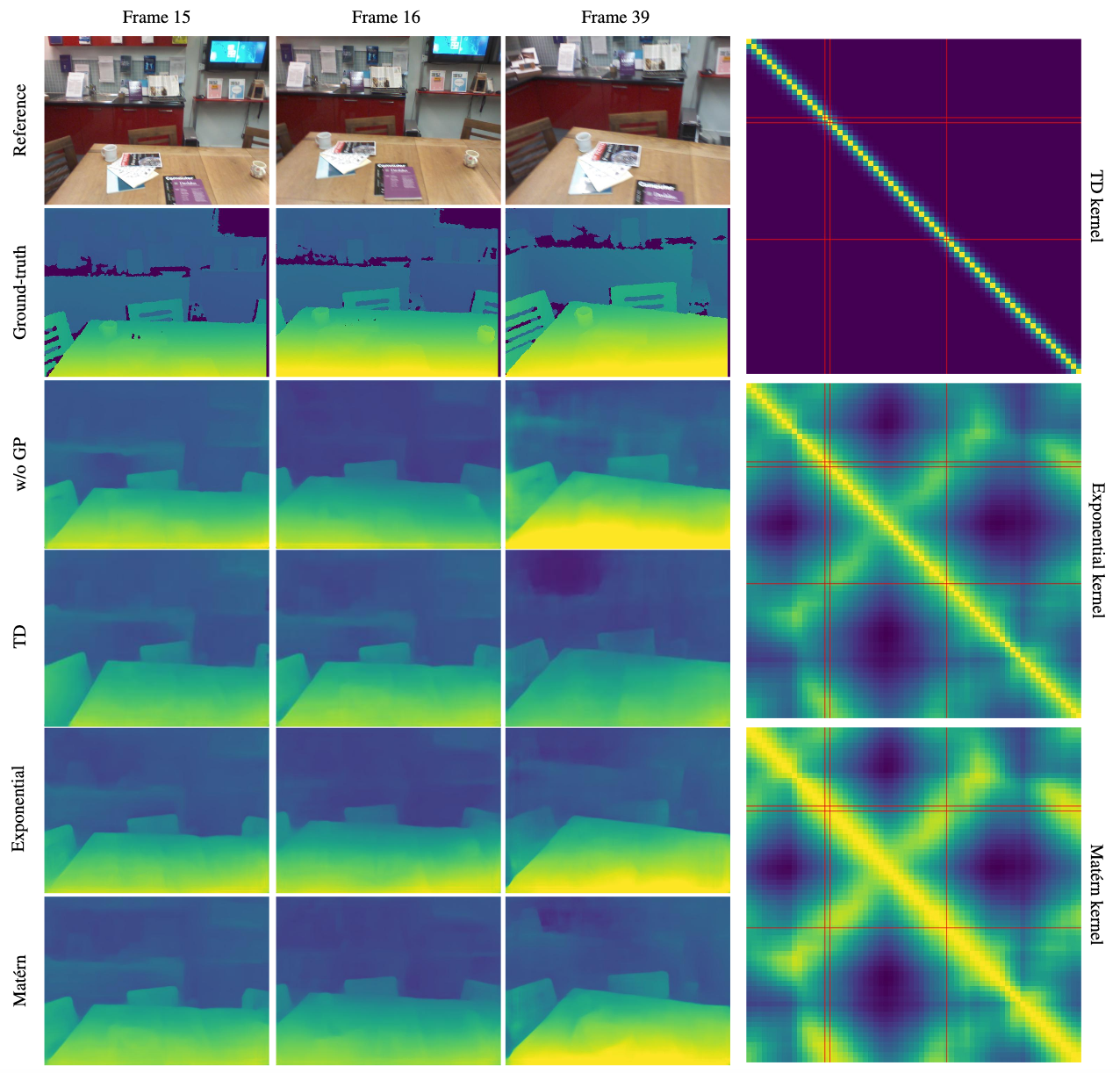
- Matern kernel used:
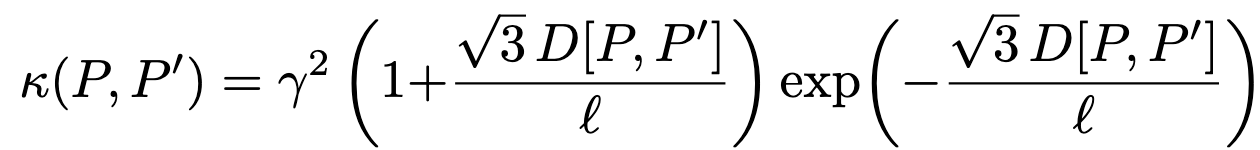
- Two learnable parameters here: amplitude and length-scale .
Gaussian Process Formulation
- Independent GP priors are placed on all latent space values for
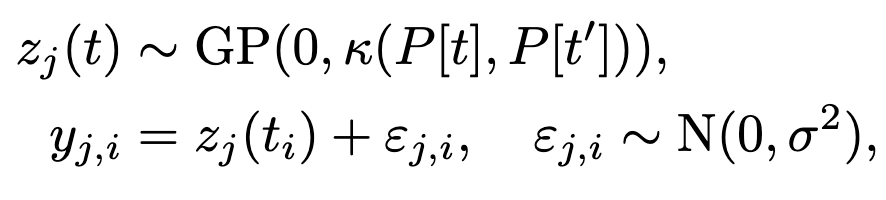
- The third learnable GP parameter is , which is the noise standard deviation.
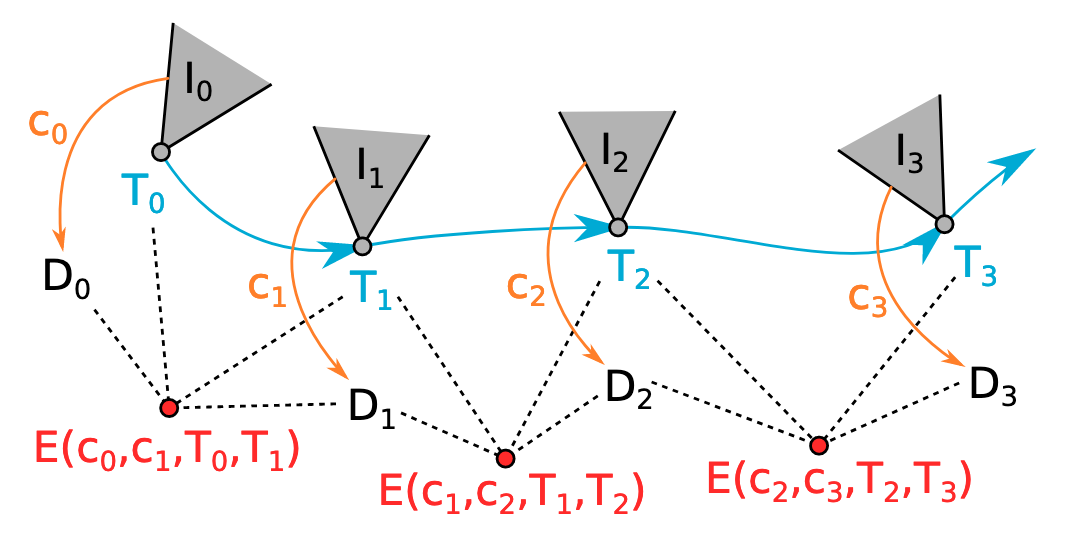
Graphical model overview (online method):
Estimation
Batch method can account for relationships between all poses while online method only has linear complexity
Batch (Offline)
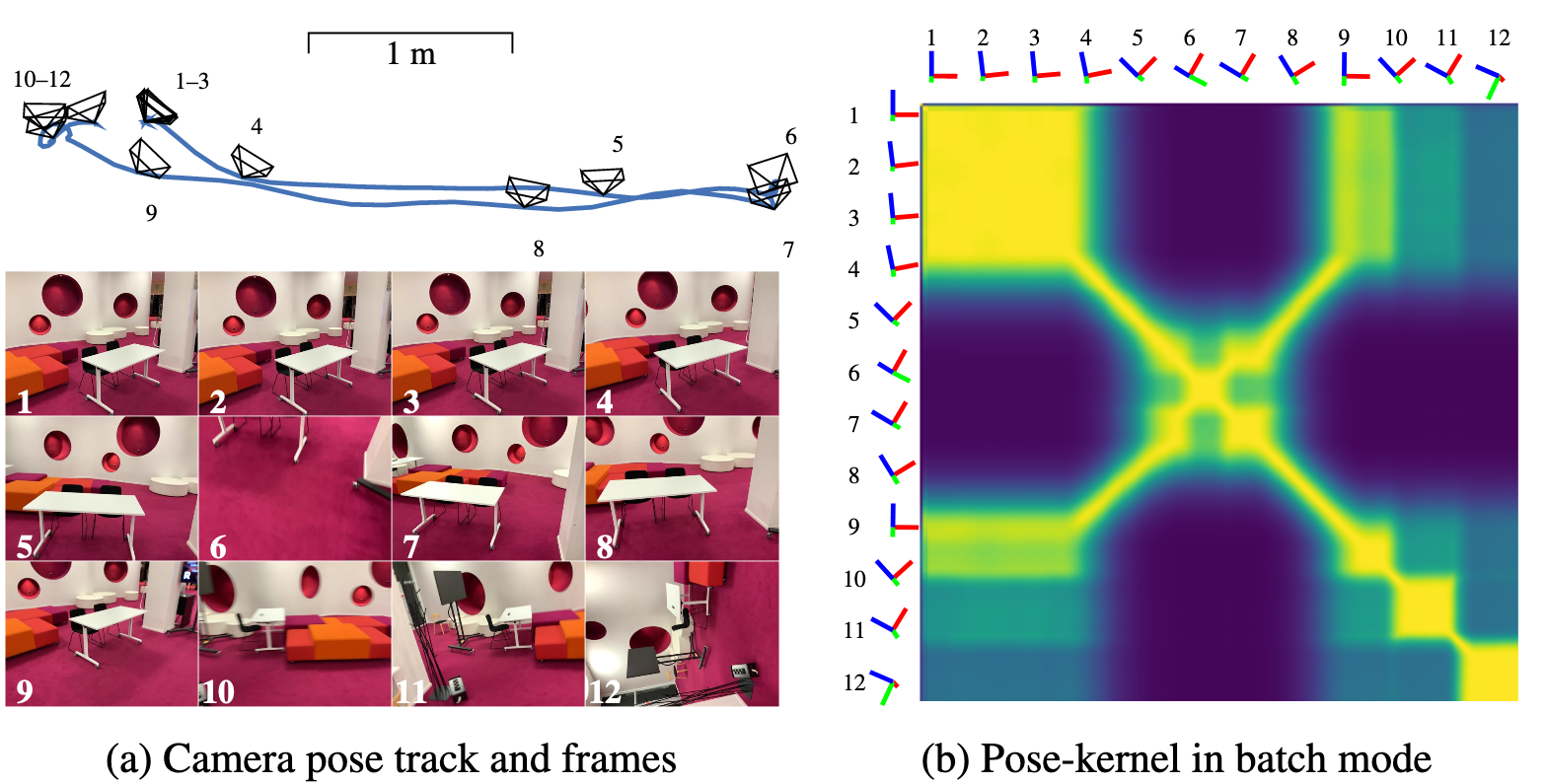
- Solve GP for all N frames
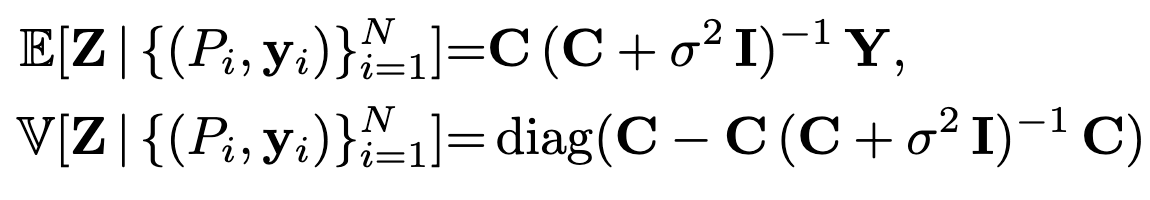
- Efficient because matrix only depends on kernel, which only depends on poses, so inverse can be shared across all subproblems.
- Posterior mean passed through decoder to retrieve the depth map
- Matrix inversion limited by number of poses, becomes too expensive after hundreds of frames
Online
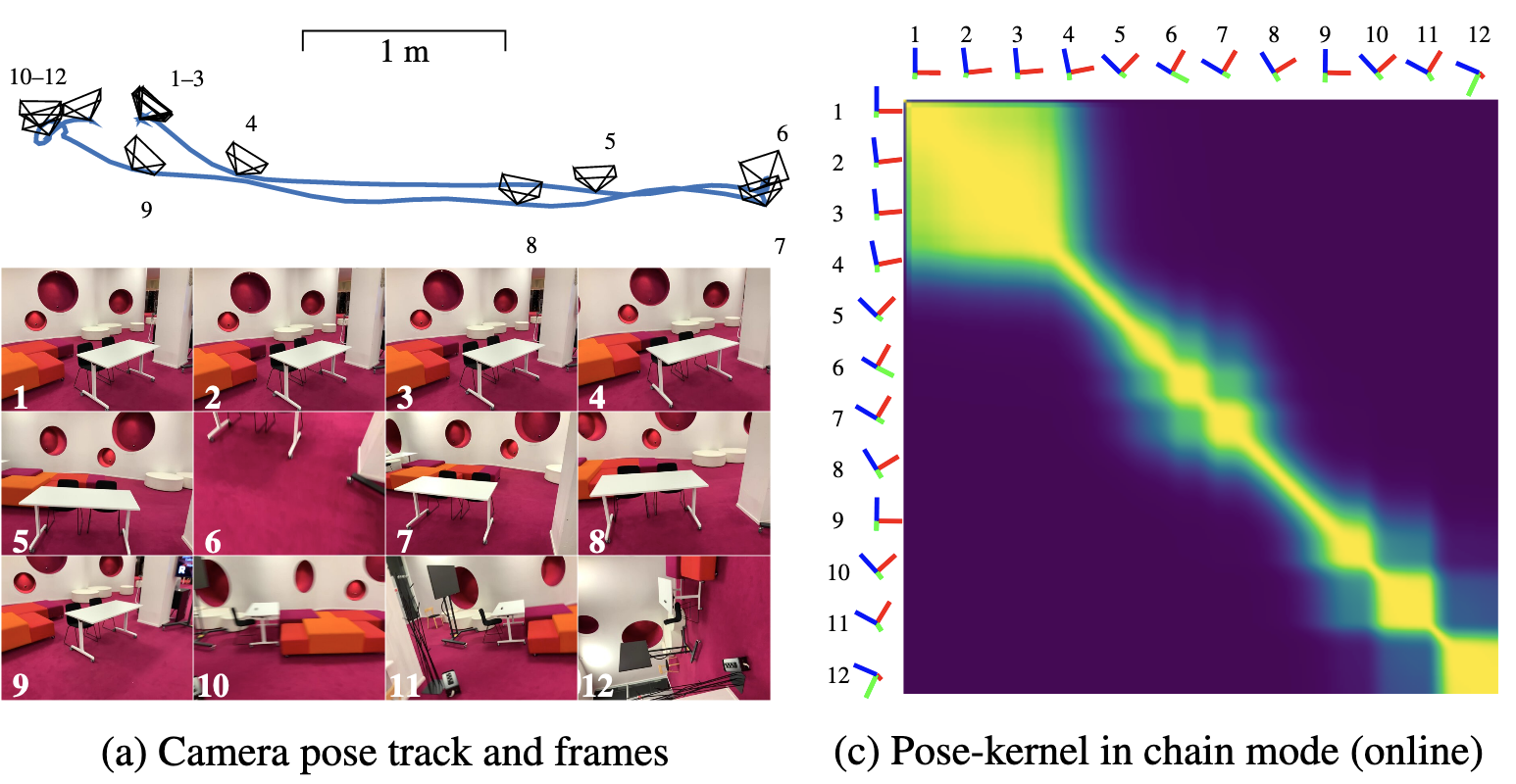
- Relax GP graphical model to be a Markov chain
- Reduce the complexity of GP from to , by reformulating it as a Kalman filtering problem
- Convert the problem to a state-space model
- Latent space encoding conditioned on all image-pose pairs up until current pair
Experiments
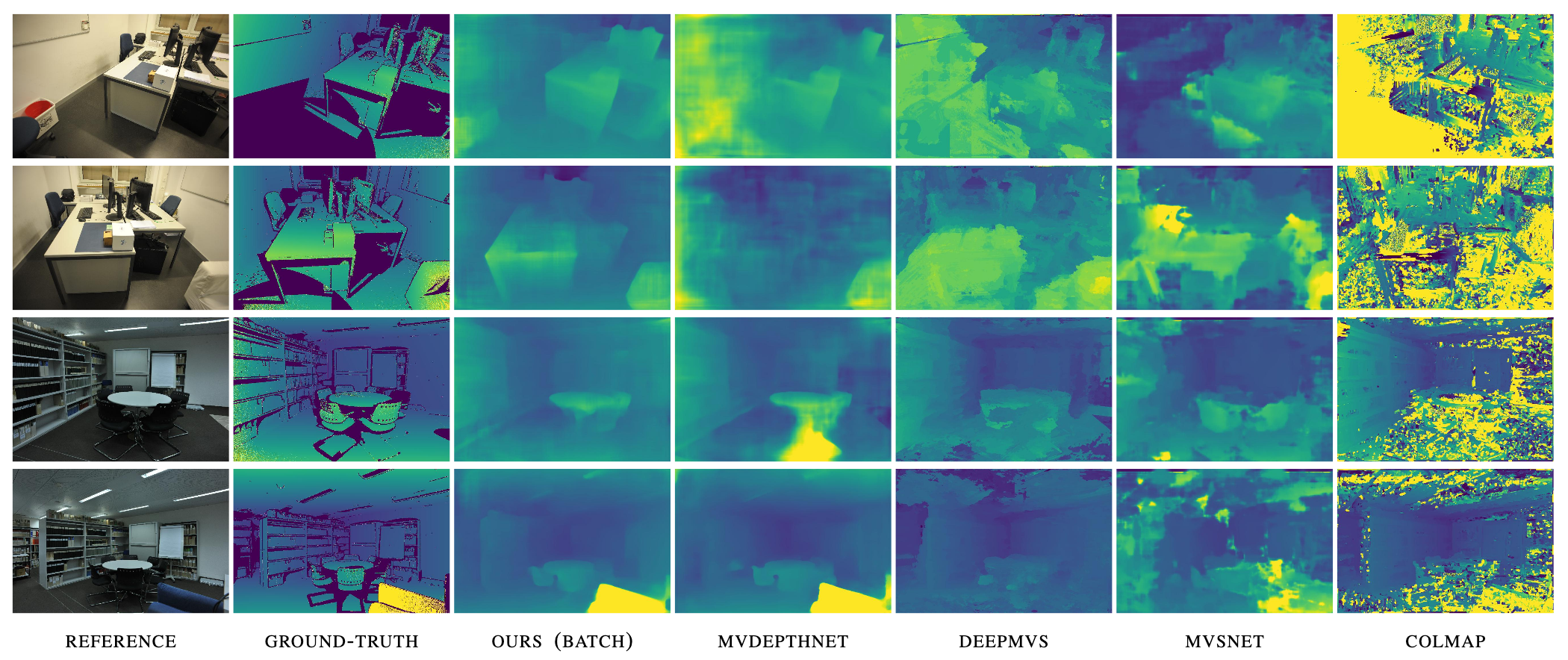
Generally results in improved results
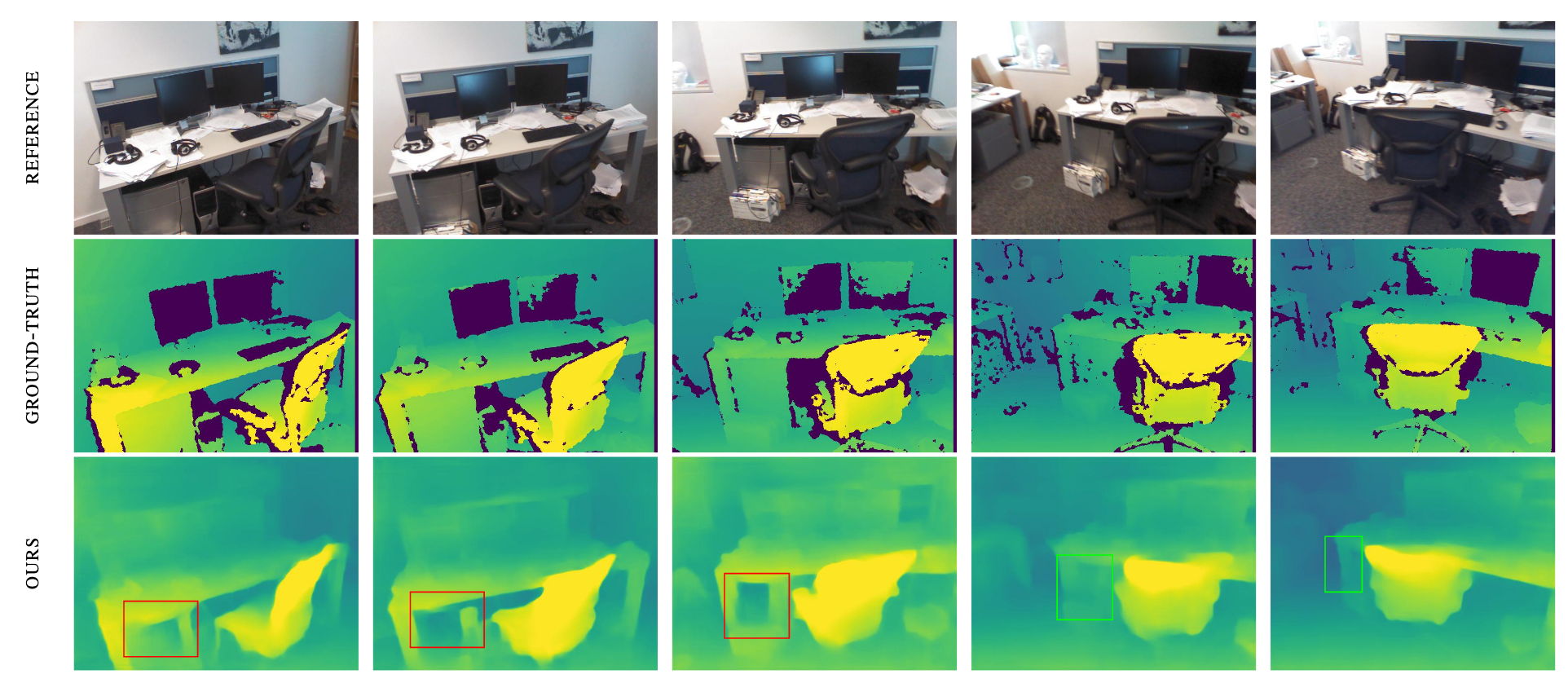
Mistakes made early in online method can take more observations to correct since they are propagated forward
Comparison of different kernels on results
This method with 2 frames outperforms other methods with 5 frames

Discussion
Online Method Limitations
- No mention of offline runtime?
- Switching to online method loses many of the benefits proposed by this formulation (online method has an implicit window-size)
Generalization
- While very efficient and provides improvement in indoor scenes, generalization should be discussed further
- Does this method help for some motions more than others? (Rotation vs. translation)
- MVDepthNet cost volume will lack information for pure rotation?
- This method can propagate future information back into past, while MVDepthNet cannot
- Gaussian Process lacks information about size of scene
- Length-scale parameter learned, but may not generalize to larger scenes
- Influence of poses within 1m very different depending on indoor vs. outdoor scene
- Kernels could be learned, but pose information alone may not be sufficient
- Computation may be severely limited if more information was included, from Section 3.3:
- "Because the likelihood is Gaussian and all the GPs share the same poses at which the covariance function is evaluated,we may solve all the 512×8×10GP regression problems with one matrix inversion. This is due to the posterior co-variance only being a function of the input poses, not values of learnt representations of images (i.e.,y does not appear in the posterior variance terms in Eq. 5)"
Graphical Models and Refinement of Latent Space
Interesting to think about ways of utilizing latent space in sequential estimation
- CodeSLAM propagates observed errors to refine latent space (geometric and photometric errors should be minimized)
- This work implicitly constrains the latent space according to hand-crafted kernel (similar poses should have similar latent spaces)
Uncertainty Estimation
- Uncertainty estimation especially useful for the downstream tasks we are interested in
- Is the uncertainty estimation from GPs useful for certain tasks?
- Useful for determining if similar data was previously seen
- Maybe not possible to propagate due to skip connections?
- Are there benefits to using GP uncertainty instead of having networks directly predict the uncertainty as an output? (https://arxiv.org/pdf/1703.04977.pdf)
- To model uncertainty, some networks commonly use loss such as
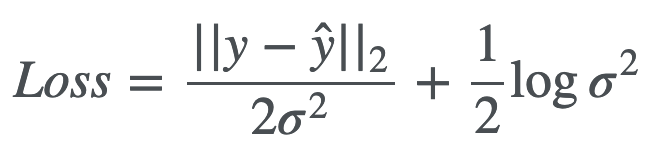
- GPs can be viewed as infinitely wide neural network layer with i.i.d. prior on weights
- GPs give more flexible models, while Bayesian NNs give more scalable models
- With enough data, is it sufficient to use neural networks?
- Examples of neural network uncertainty usage in dense SLAM
- CodeSLAM: https://arxiv.org/pdf/1804.00874.pdf